Recent state-of-the-art approaches for embodied learning via interaction directly employ large language models (LLMs) as
agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM
agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however,
frequently calling LLMs is slow and expensive. This begs an interesting question: Instead of directly employing LLMs as
embodied agents, can we use LLMs’ reasoning capabilities to adaptively create training environments to help smaller
embodied RL agents learn useful skills that they are weak at?
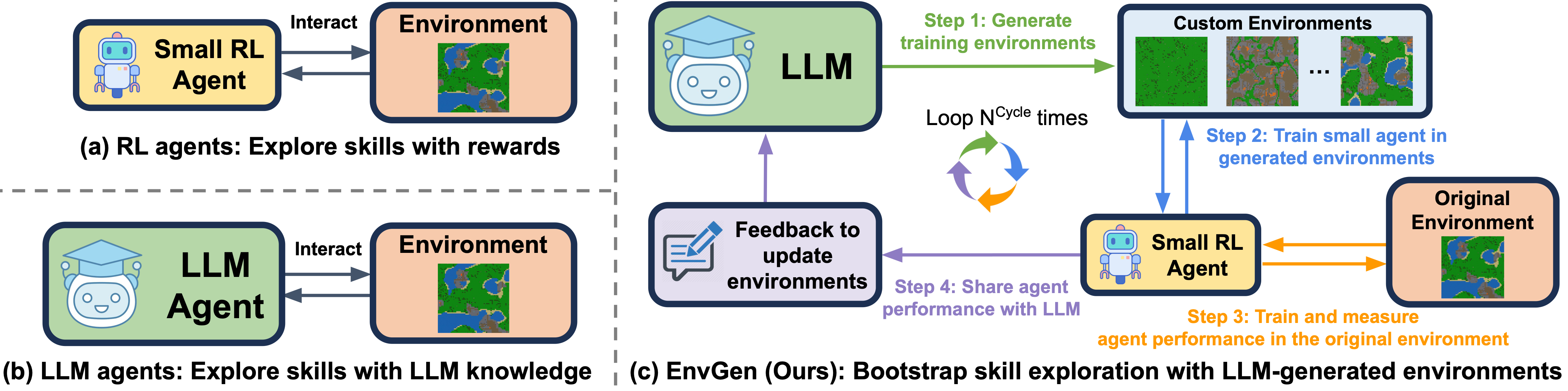
In this work, we propose EnvGen, a novel framework to
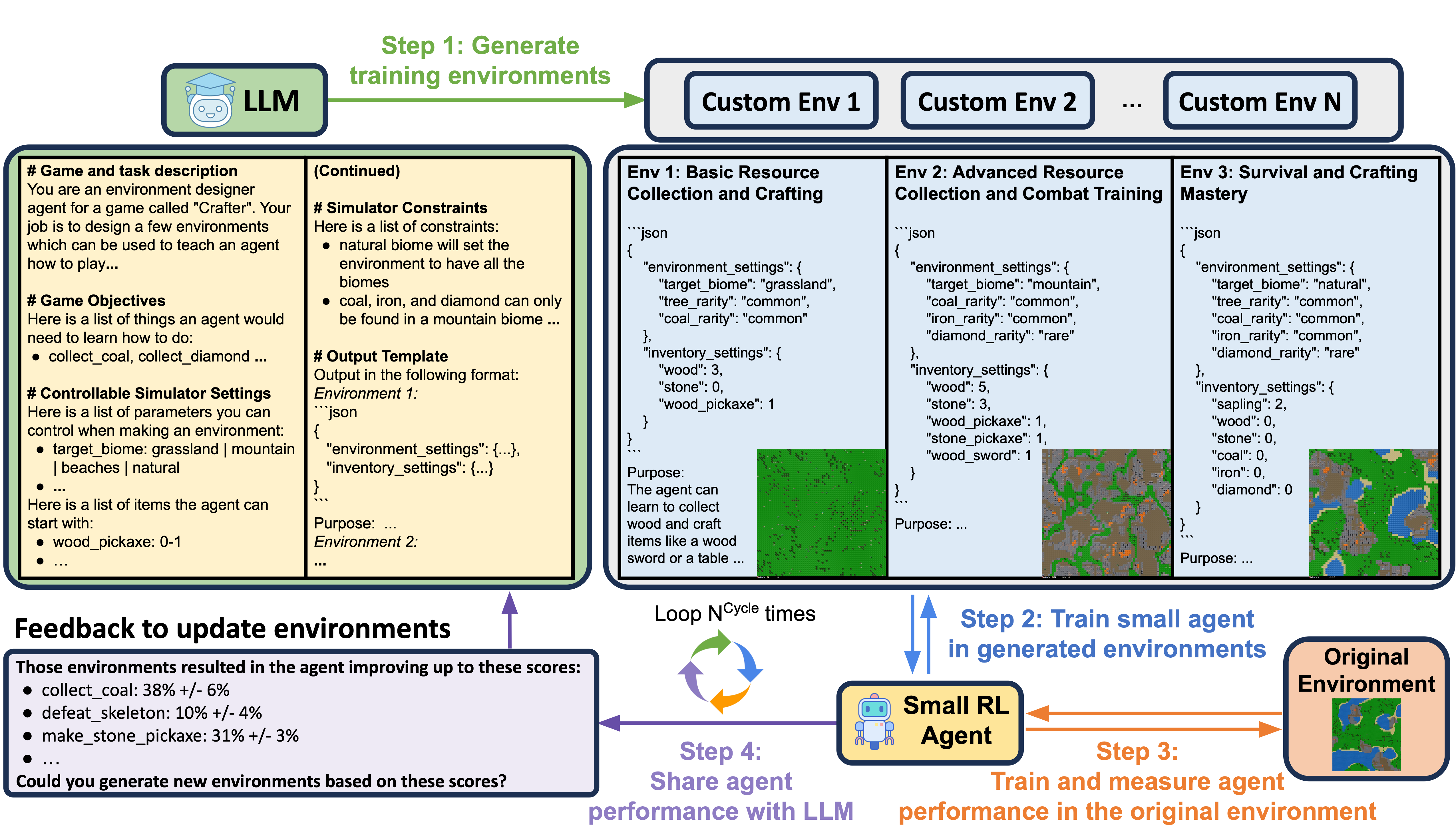
address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn
different tasks in parallel. Concretely, the LLM is given the task description and environment simulator objectives that
the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains,
items initially given to agents, chance of finding certain objects, etc.). Next, we train a small RL agent in a mixture
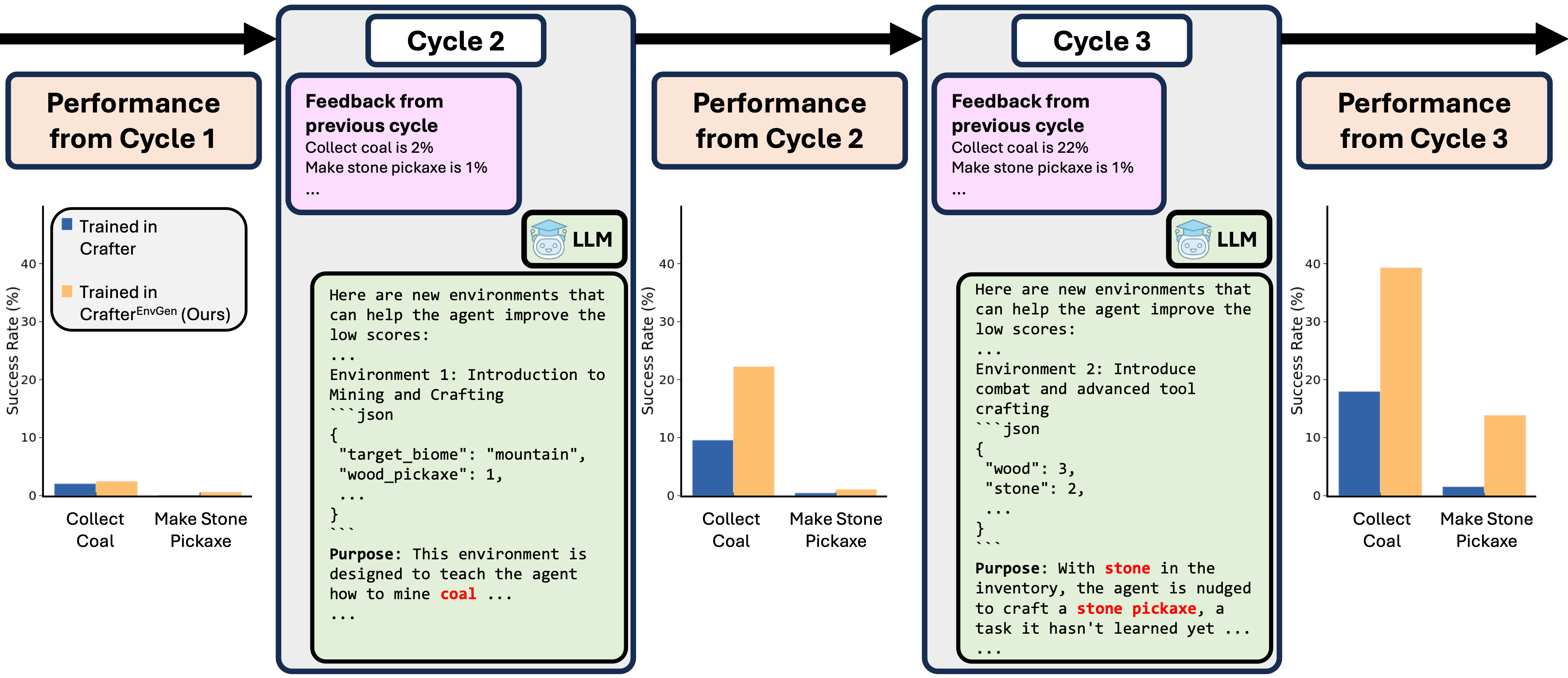
of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments
to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the
agent's performance.
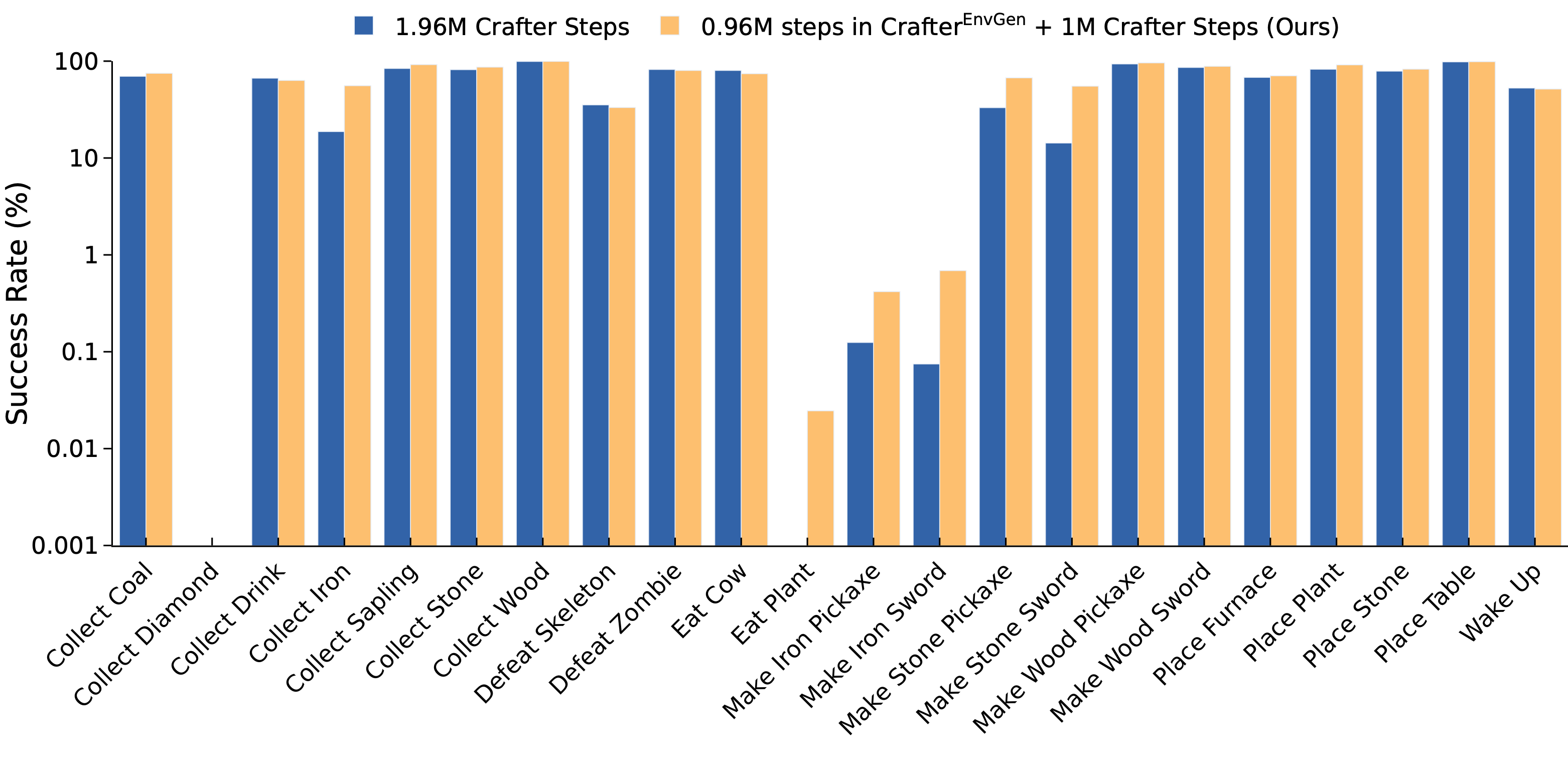
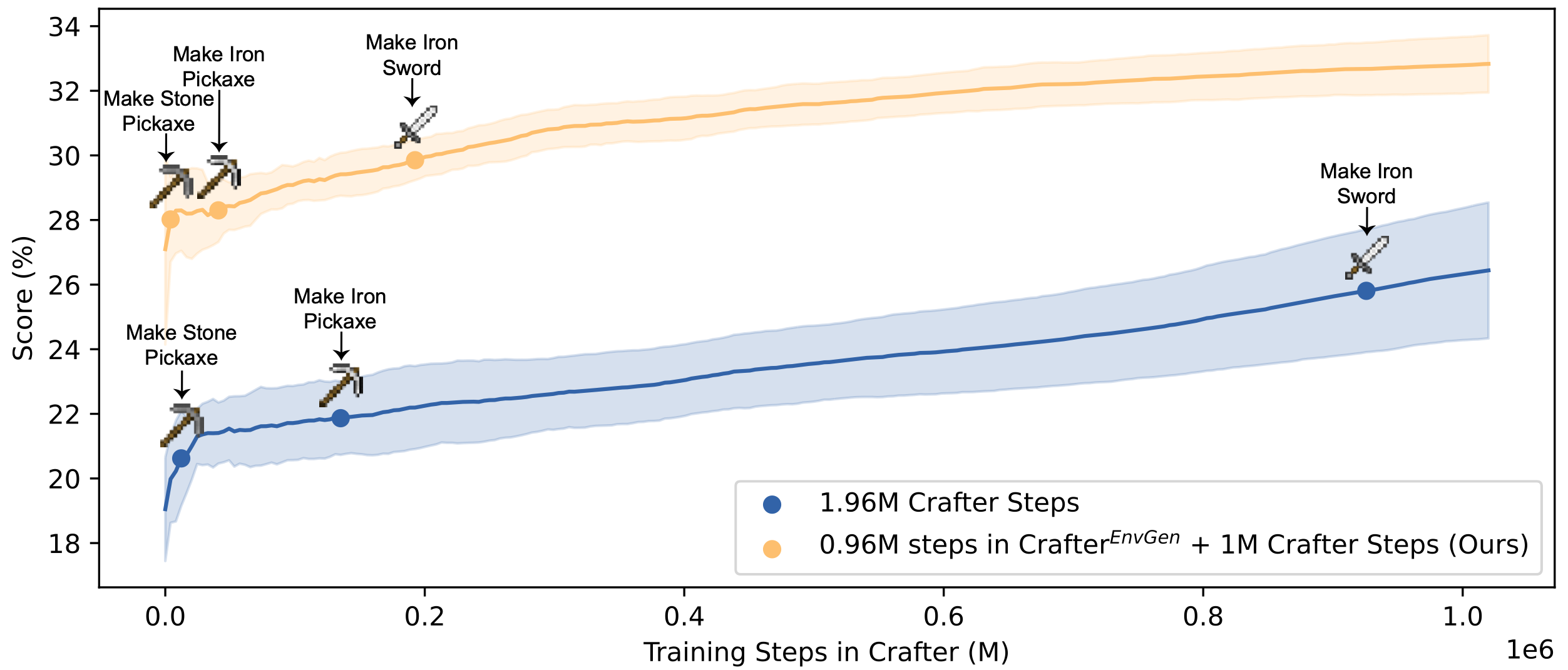
We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist game
environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent,
and learns longhorizon tasks significantly faster. We also show qualitatively how the LLM adapts training environments
to help improve RL agents' weaker skills over time.
We also show that using an LLM to adapt environments dynamically outperforms curriculum learning approaches and
how the LLM adapts training environments to help improve RL agents' weaker skills over time.
Additionally, EnvGen is substantially more efficient as it only uses
a small number of LLM calls (e.g., 4 in total), whereas LLM agents require one or more LLM calls per step (resulting in
thousands of LLM calls per episode). Lastly, we present detailed ablation studies for EnvGen's design choices.